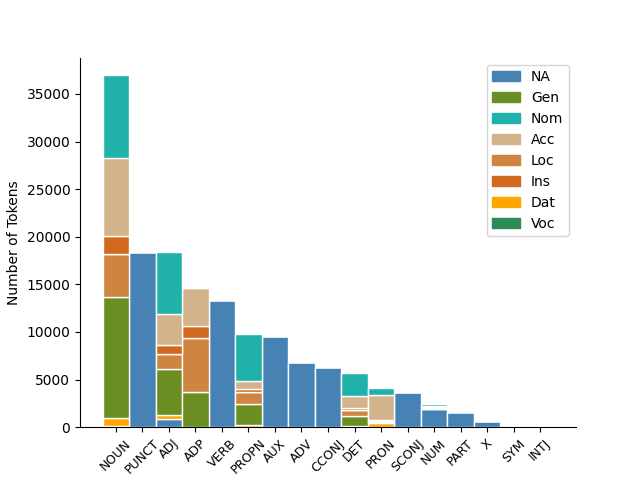
Token Distribution across Case feature
The following histogram captures the token distribution per different part-of-speech (POS) tags.
Legend on the top-right shows the different values the Case attribute takes.
'NA' denotes those tokens which do not possess the Case attribute.